Note
Go to the end to download the full example code.
Sketch-Map#
This example demonstrates the SketchMap estimator for
nonlinear dimensionality reduction.
Sketch-map is a method introduced in [Ceriotti2011] that projects high-dimensional data
into a low-dimensional space while preserving distances in a nonlinear way. Unlike
methods like PCA that try to preserve absolute distances, sketch-map uses sigmoid
functions to focus on intermediate distances while being less sensitive to very small or
very large ones. The key idea is that distances below a cutoff sigma are compressed
(treated as “close”), distances above sigma*(a/b) are expanded (treated as “far”),
and intermediate distances are mapped smoothly between these regimes.
Basic simple example#
We’ll start with the classic swiss roll - a 2D manifold embedded in 3D space and compare the projection using PCA and Sketchmap.
import matplotlib.pyplot as plt
import numpy as np
from sklearn.datasets import make_blobs, make_swiss_roll
from sklearn.decomposition import PCA
from sklearn.metrics import pairwise_distances
from skmatter.decomposition import SketchMap
from skmatter.sample_selection import FPS
X, color = make_swiss_roll(n_samples=500, noise=0.5, random_state=42)
print(f"Swiss roll data shape: {X.shape}")
Swiss roll data shape: (500, 3)
Fit SketchMap with automatic parameter estimation.
When params=None, the algorithm estimates values based on the distance
distribution in the input data.
sm = SketchMap(n_components=2, verbose=True)
embedding = sm.fit_transform(X)
print(f"\nEstimated parameters: {sm.params_}")
Fitting Sketch-Map: 500 samples, 3 features
Data centered
Computing pairwise distances...
Using auto-estimated sigmoid parameters:
sigma = 14.4842
a_high = 2.43, b_high = 4.86
a_low = 1.62, b_low = 1.62
(peak distance = 16.0935)
Using uniform weights (total_weight = 124750)
Initializing with classical MDS...
=== Stage 0: MDS optimization (100 steps) ===
Optimization finished: stress = 11.222973
MDS stress: 11.222973
=== Stage 1: Pre-optimization (100 steps) ===
Optimization finished: stress = 0.015573
Pre-optimization stress: 0.015573
=== Stage 2: Main optimization (1000 steps) ===
Optimization finished: stress = 0.015573
Final stress: 0.015573
Sketch-Map fitting complete!
Estimated parameters: {'sigma': np.float64(14.484184608046293), 'a_high': np.float64(2.4309512520915053), 'b_high': np.float64(4.861902504183011), 'a_low': np.float64(1.6206341680610035), 'b_low': np.float64(1.6206341680610035)}
Visualize the embedding and compare with PCA
Compute PCA embedding for comparison
pca = PCA(n_components=2)
embedding_pca = pca.fit_transform(X)
fig, axes = plt.subplots(1, 3, figsize=(15, 5))
# Original data
axes[0].scatter(X[:, 0], X[:, 2], c=color, cmap="viridis", s=20)
axes[0].set_title("Original Swiss Roll (X vs Z)")
axes[0].set_xlabel("X")
axes[0].set_ylabel("Z")
# PCA embedding
sc = axes[1].scatter(
embedding_pca[:, 0], embedding_pca[:, 1], c=color, cmap="viridis", s=20
)
axes[1].set_title("PCA embedding")
axes[1].set_xlabel("PC1")
axes[1].set_ylabel("PC2")
# SketchMap embedding
sc = axes[2].scatter(embedding[:, 0], embedding[:, 1], c=color, cmap="viridis", s=20)
axes[2].set_title("SketchMap embedding")
axes[2].set_xlabel("Dimension 1")
axes[2].set_ylabel("Dimension 2")
plt.colorbar(sc, ax=axes[2], label="Position along roll")
plt.tight_layout()
plt.show()
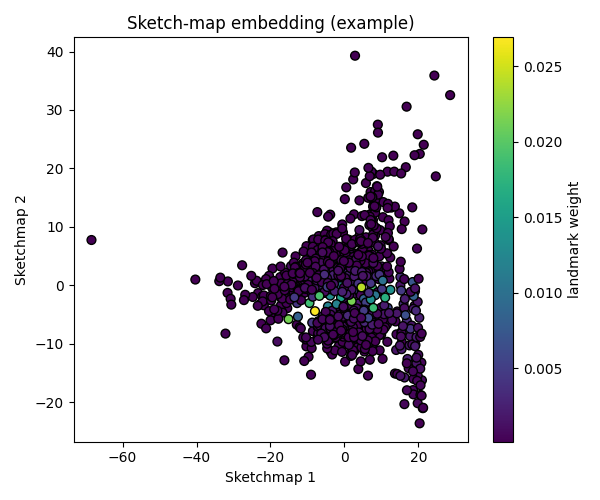
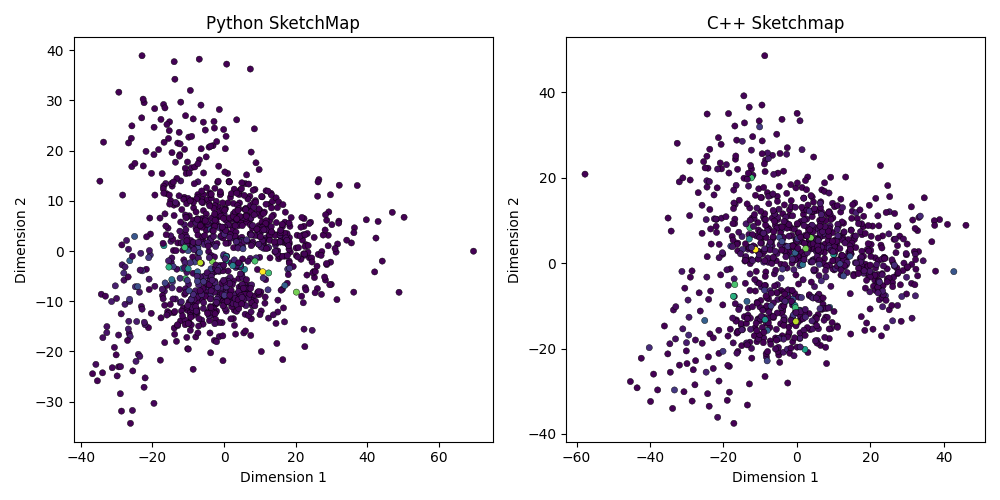
MAD test projection - comparison with C++ sketchmap reference#
Here we compare the Python implementation against the original C++ code using the MAD (Massive Atomic Diversity) dataset [Mazitov2025a]. The input data includes representative points (landmarks) and their associated Voronoi weights, obtained from the test split of the MAD dataset. These landmarks were selected using FPS on the PET-MAD [Mazitov2025b] last-layer features.
The weights come from a Voronoi tessellation used when selecting landmark points. Each weight represents the fraction of the data that falls into the Voronoi cell around that landmark.
Load high-dimensional landmarks (1000 samples, 1024 features + weight):
data = np.loadtxt("highd-landmarks")
X_hd = data[:, :-1]
weights = data[:, -1]
print(f"Loaded {X_hd.shape[0]} landmarks with {X_hd.shape[1]} features")
print(f"Weights range: [{weights.min():.4f}, {weights.max():.4f}]")
Loaded 1000 landmarks with 1024 features
Weights range: [0.0001, 0.0269]
We also load reference 2D embedding obtained using the original C++ implementation of sketchmap, for comparison.
lowd_cpp = np.loadtxt("low_landmarks.dat", comments="#")
lowd_cpp = lowd_cpp[:, :2]
print(f"C++ reference embedding shape: {lowd_cpp.shape}")
C++ reference embedding shape: (1000, 2)
Fit SketchMap with the same parameters as the C++ reference.
The sample_weights parameter allows each landmark to contribute differently to the
optimization: landmarks in denser regions (higher weight) influence the
low-dimensional embedding more, while sparse region landmarks contribute less.
The params argument specifies the sigmoid parameters obtained following the
analysis described at https://sketchmap.org/index.html?page=tuts&psub=analysis.
The global_opt_steps parameter controls global optimization, which helps escape
local minima and is highly recommended for use. Here, we use only 3 steps, you can
experiment with higher values!
Fitting Sketch-Map: 1000 samples, 1024 features
Data centered
Computing pairwise distances...
Using sigmoid parameters (user + auto-estimated):
sigma = 7.0000
a_high = 4.00, b_high = 2.00
a_low = 2.00, b_low = 2.00
(peak distance = 10.3644)
Using sample weights (total_weight = 0.4965)
Initializing with classical MDS...
=== Stage 0: MDS optimization (100 steps) ===
Optimization finished: stress = 5.442095
MDS stress: 5.442095
=== Stage 1: Pre-optimization (100 steps) ===
Optimization finished: stress = 0.012522
Pre-optimization stress: 0.012522
=== Stage 2: Main optimization (1000 steps) ===
Optimization finished: stress = 0.012522
Final stress: 0.012522
=== Global optimization (basin hopping, 4 iter) ===
Basin hopping finished: stress = 0.012236
Sketch-Map fitting complete!
Plot comparison
fig, axes = plt.subplots(1, 2, figsize=(10, 5))
# Python embedding
axes[0].scatter(
lowd_py[:, 0], lowd_py[:, 1], c=weights, cmap="viridis", s=20, edgecolor="k", lw=0.3
)
axes[0].set_title("Python SketchMap")
axes[0].set_xlabel("Dimension 1")
axes[0].set_ylabel("Dimension 2")
# C++ embedding
axes[1].scatter(
lowd_cpp[:, 0],
lowd_cpp[:, 1],
c=weights,
cmap="viridis",
s=20,
edgecolor="k",
lw=0.3,
)
axes[1].set_title("C++ Sketchmap")
axes[1].set_xlabel("Dimension 1")
axes[1].set_ylabel("Dimension 2")
plt.tight_layout()
plt.show()
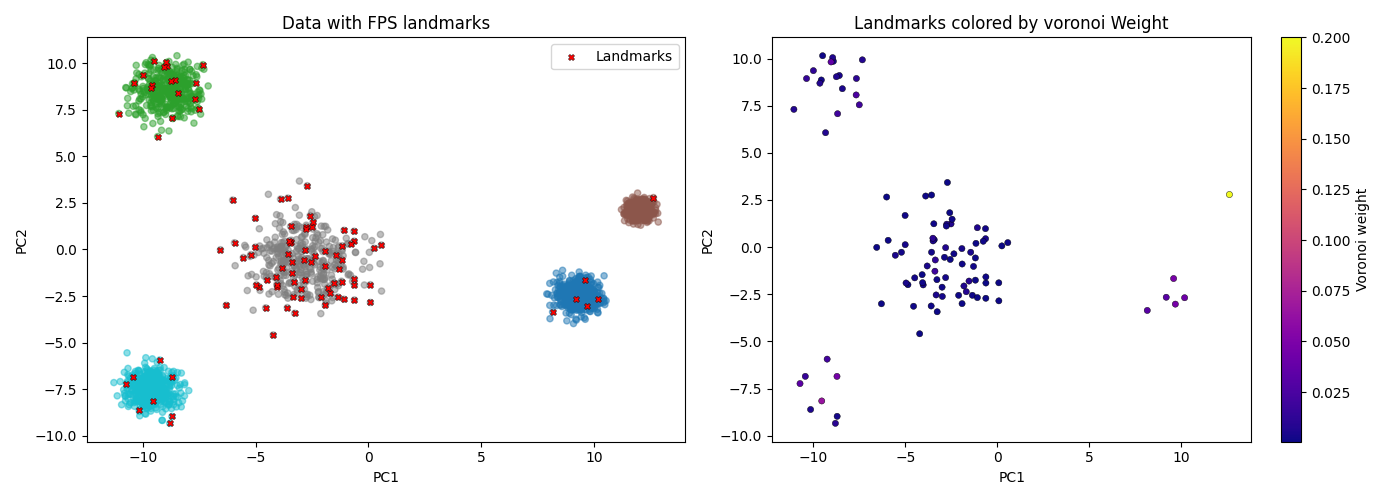
Computing Voronoi weights with skmatter#
If you’re selecting landmarks, e.g. using skmatter.FPS, you can compute Voronoi weights: after selecting landmarks, assign each point in the full dataset to its nearest landmark. The weight of each landmark is the count (or sum of weights) of points assigned to it.
def compute_voronoi_weights(X_full, X_landmarks, input_weights=None):
"""
For each landmark, count how many points from the full dataset are closest to it
(i.e., fall within its Voronoi cell)
Parameters
----------
X_full : ndarray of shape (n_samples, n_features)
The full dataset from which landmarks were selected.
X_landmarks : ndarray of shape (n_landmarks, n_features)
The selected landmark points.
input_weights : ndarray of shape (n_samples,), optional
Weights for each point in X_full. If None, each point has weight 1.
"""
if input_weights is None:
input_weights = np.ones(X_full.shape[0])
# Compute distances from all points to all landmarks
distances = pairwise_distances(X_full, X_landmarks)
# Assign each point to its nearest landmark
assignments = np.argmin(distances, axis=1)
# Sum weights for each landmark's Voronoi cell
weights = np.zeros(X_landmarks.shape[0])
for i, landmark_idx in enumerate(assignments):
weights[landmark_idx] += input_weights[i]
# Normalize to sum to 1
weights /= weights.sum()
return weights
Select landmarks with FPS and compute their Voronoi weights. We’ll use a dataset with variable density to see meaningful weight differences.
X_varied, labels_varied = make_blobs(
n_samples=2000,
n_features=5,
centers=5,
cluster_std=[0.5, 0.8, 0.3, 1.2, 0.6], # variable cluster sizes
random_state=42,
)
Select 100 landmarks using FPS
n_landmarks = 100
fps = FPS(n_to_select=n_landmarks, random_state=42)
fps.fit(X_varied)
landmark_ids = fps.selected_idx_
X_landmarks_varied = X_varied[landmark_ids]
Compute Voronoi weights
voronoi_weights = compute_voronoi_weights(X_varied, X_landmarks_varied)
print(f"Selected {n_landmarks} landmarks")
print(
f"Voronoi weights: min={voronoi_weights.min():.4f}, max={voronoi_weights.max():.4f}"
)
Selected 100 landmarks
Voronoi weights: min=0.0005, max=0.2000
Visualize the landmarks with their Voronoi weights. Project to 2D:
pca_viz = PCA(n_components=2)
X_varied_2d = pca_viz.fit_transform(X_varied)
X_landmarks_2d = pca_viz.transform(X_landmarks_varied)
fig, axes = plt.subplots(1, 2, figsize=(14, 5))
# Original data with landmarks highlighted
axes[0].scatter(
X_varied_2d[:, 0], X_varied_2d[:, 1], c=labels_varied, cmap="tab10", s=20, alpha=0.5
)
axes[0].scatter(
X_landmarks_2d[:, 0],
X_landmarks_2d[:, 1],
c="red",
s=20,
edgecolor="k",
lw=0.3,
marker="X",
label="Landmarks",
)
axes[0].set_title("Data with FPS landmarks")
axes[0].set_xlabel("PC1")
axes[0].set_ylabel("PC2")
axes[0].legend()
# Landmark weights
sc = axes[1].scatter(
X_landmarks_2d[:, 0],
X_landmarks_2d[:, 1],
c=voronoi_weights,
cmap="plasma",
s=20,
edgecolor="k",
lw=0.3,
)
axes[1].set_title("Landmarks colored by voronoi Weight")
axes[1].set_xlabel("PC1")
axes[1].set_ylabel("PC2")
plt.colorbar(sc, ax=axes[1], label="Voronoi weight")
plt.tight_layout()
plt.show()
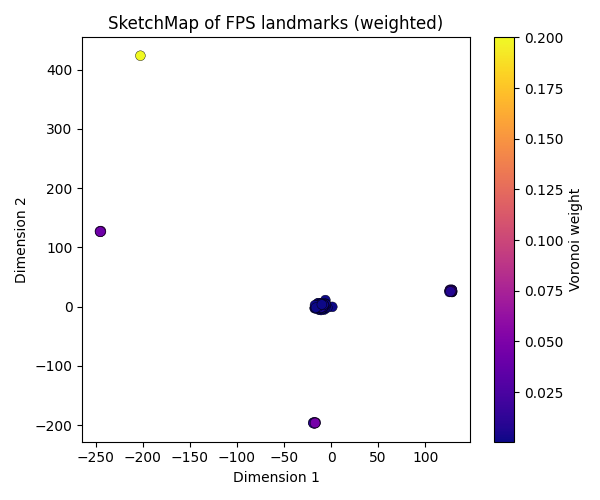
Use these weights with SketchMap for a weighted embedding
sm_weighted = SketchMap(
n_components=2, random_state=42, global_opt_steps=10, verbose=True
)
embedding_landmarks = sm_weighted.fit_transform(
X_landmarks_varied, sample_weights=voronoi_weights
)
fig, ax = plt.subplots(figsize=(6, 5))
sc = ax.scatter(
embedding_landmarks[:, 0],
embedding_landmarks[:, 1],
c=voronoi_weights,
cmap="plasma",
s=50,
edgecolor="k",
lw=0.3,
)
ax.set_title("SketchMap of FPS landmarks (weighted)")
ax.set_xlabel("Dimension 1")
ax.set_ylabel("Dimension 2")
plt.colorbar(sc, ax=ax, label="Voronoi weight")
plt.tight_layout()
plt.show()
Fitting Sketch-Map: 100 samples, 5 features
Data centered
Computing pairwise distances...
Using auto-estimated sigmoid parameters:
sigma = 4.5027
a_high = 2.69, b_high = 5.38
a_low = 1.08, b_low = 1.08
(peak distance = 5.0030)
Using sample weights (total_weight = 0.4693)
Initializing with classical MDS...
=== Stage 0: MDS optimization (100 steps) ===
Optimization finished: stress = 1.500134
MDS stress: 1.500134
=== Stage 1: Pre-optimization (100 steps) ===
Optimization finished: stress = 0.001165
Pre-optimization stress: 0.001165
=== Stage 2: Main optimization (1000 steps) ===
Optimization finished: stress = 0.001165
Final stress: 0.001165
=== Global optimization (basin hopping, 10 iter) ===
Basin hopping finished: stress = 0.001165
Sketch-Map fitting complete!
References#
Mazitov, A., Chorna, S., Fraux, G. et al. Massive Atomic Diversity: a compact universal dataset for atomistic machine learning. Sci Data 12, 1857 (2025). https://doi.org/10.1038/s41597-025-06109-y
Mazitov, A., Bigi, F., Kellner, M. et al. PET-MAD as a lightweight universal interatomic potential for advanced materials modeling. Nat Commun 16, 10653 (2025). https://doi.org/10.1038/s41467-025-65662-7